고정 헤더 영역
상세 컨텐츠
본문 제목
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문 한글 번역 - 4
본문
BERT논문을 직역 및 의역으로 작성한 내용입니다.
3 BERT는 다음 컨텐츠를 이용바랍니다.
https://ynebula.tistory.com/55
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 논문 한글 번역 - 3.1-3.2
BERT논문을 직역 및 의역으로 작성한 내용입니다. 3.1 Pre-training BERT Peter et al(2018a), Radford et al(2018)과 다르게, 우리는 BERT를 pre-train하기 위해 traditional left-to-right or right-to-left lan..
ynebula.tistory.com
4 Experiments
이번 Section에서는 11 NLP 과제에서 BERT fine-tuning한 결과를 알아 보겠습니다.
4.1 GLUE

General Lanuage Understanding Evaluation(GLUE) benchmar(Wang et al., 2018a)은 다양한 자연어 이해 과제입니다. 자세한 설명은 부록 B.1에 있습니다.
GLUE를 fine-tune하기 위해서, input sequnce를 Section 3에서 설명 했듯이 표현했습니다(single sentence or sentence pairs). 그리고 final hidden vector C를 사용했습니다(C∈RH). C는 집계 표현으로 첫번째 token ([CLS]) 입니다. Fine-tuning동안 새롭게 사용된 parameter는 classification layer weight W 입니다(W∈RK*H). K는 label입니다. 우리는 C와 W로 classification loss를 연산하였습니다(i.e. log(softmax(CWT))).
우리는 모든 task에서 batch size:32, fine-tune:3 epoch로 설정했습니다. 각 task에서 우리는 Dev set에서 learning rate를 5e-5, 4e-5, 3e-5, 2e-5 중 가장 좋은 fine-tune을 선택했습니다. 게다가 BERTLARGE에서 우리는 fine-tuning이 작은 datasets에서 가끔 불안정 하다는 것을 확인했습니다. 그래서 우리는 무작위로 몇 번 재시작을 수행했고 best model을 선택하였습니다. 우리는 같은 pre-trained checkpoint를 사용했지만 data shuffling과 classifier layer initialization으로 여러번 fine-tuning을 수행했습니다.
결과는 Table 1에서 확인할 수 있습니다. BERTBASE와 BERTLARGE 모두 상당한 차이로 더 좋은 결과를 냈습니다. 이전 SOTA보다 평균 accuracty가 4.5% ~ 7% 향상되었습니다. BERTBASE와 OpenAI GPT는 attention masking을 제외하고 거의 같은 model architecture 조건입니다. MNLI에서 BERT가 4.6% 더 높은 정확도를 보였습니다. GLUE leaderboard에서 BERTLARGE는 80.5 점을 받았습니다(OpenAI GPT: 72.8점).
우리는 매우 적은 training data로 모든 task에서 BERTLARGE와 BERTBASE 모두 높은 성능을 확인했습니다. model size의 효과는 Section 5.2에서 확인할 수 있습니다.
4.2 SQuAD v1.1
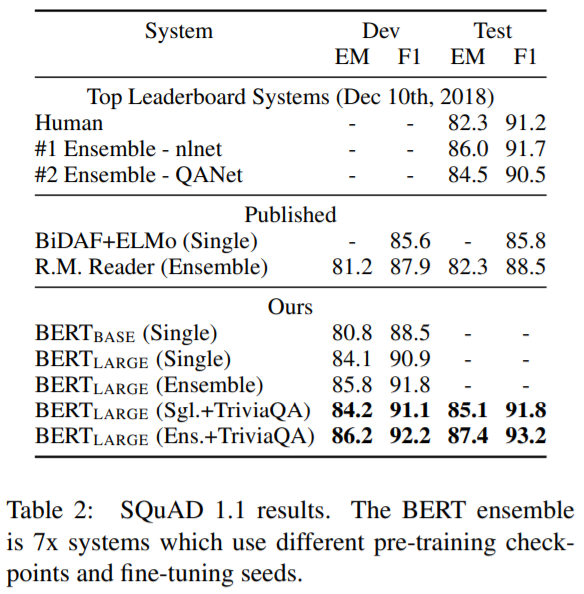
Stanford Question Answering Dataset(SQuAD v1.1)은 100.000개 crowdsource 한 질문/답변 쌍 컬렉션입니다. 주어진 질문과 답변을 포한하는 위키피디아의 구절을 이용해서, Task는 구절에 있는 answer text span을 예측합니다. Figure 1에서 보듯이, 질문 답변 task에서 우리는 single packed sequence로 input question과 passage를 표현했습니다. 즉, A embedding을 사용하여 질문으로, 그리고 B embedding을 사용하여 구절로 사용했습니다. 우리는 fine-tuning동안 start vector S와 end vector를 사용했습니다(S∈RH, E∈RH). answer span의 시작 work i의 확률은 Ti와 S사이를 dot product로 연산합니다. 다음에 단락의 모든 단어를 softax연산합니다.
answer span의 end에도 유사식이 사용됩니다. from position i에서 to position의 candidate span의 점수는 S·Ti + E·Tj 로정의됩니다. 그리고 maximum scoring span이 예측으로 사용됩니다 (j>=i). 훈련의 목표는 올바를 start와 end의 log-likelihoods의 합 입니다. 우리는 3 epoch, learning rate: 5e-5, batch size:32로 fine-tune 하였습니다.
Table 2에서 top published systems(Seo et al., 2017; Clark and Gardner. 2018; Peters et al., 2018a; Hu et al., 2018) 와 top leaderboard entiris를 확인할 수 있습니다. SQuAD leaderboard의 top 결과는 최신 public system descriptions를 갖지 못 했습니다. 그래서 우리는 SQuAD를 fine-tuing하기 전에,TriviaQA로 처음 fine-tuning하여 약간의 data argumentation으로 사용했습니다.
우리의 best performing system은 ensembling에서 top leaderboard system보다 +1.5 F1 성능을 냈습니다. 그리고 single system에서는 +1.3 F1 성능을 냈습니다. 사실상 single BERT model은 F1 score의 top ensemble system 성능을 냈습니다. TriviaQA fine-tuing없이는 0.1-0.4 F1 낮았습니다. 예전 system보다는 좋은 성능을 냈습니다.
4.3 SQuAD v2.0

SQuAD v2.0과제는 좀 더 현실적으로 만들고 짧은 답변이 제시된 단락에 없다는 가능성을 허용하므로써 SQuAD v1.1문제 정의를 확장하였습니다. 우리는 이 과제를 위해 SQuAD v1.1 BERT 모델을 확장 시켰습니다. 우리는 답이 없는 질문을 [CLS] token에서 시작부터 끝의 답변 범위를 가지는 것으로 처리했습니다. [CLS] token의 위치를 포함하기 위해 시작과 종료 답변 범위 위치의 확률 공간을 확장하였습니다. 예측을 위해, 우리는 답변이 없는 범위의 점수를 계산합니다(snull=S·C+ E·C). non-null 범위의 점수는 si,j=maxj>=.S·Ti + E·Tj 입니다(이 결과는 추정치 임). 우리는 non-null 답변을 예측하였습니다(si,j (햇-추정치)> snull + τ) (τ(threshold)은 maximize F1의 dev set에서 선택됩니다). 우리는 TriviaQA data를 사용하지 않았습니다. 우리는 2epochs, learing rate 5e-5, batch size: 48로 fine-tuen 하였습니다.
이번 leaderboard entry들과 top publiahed work와 비교한 결과는 Table 3에서 볼 수 있습니다. 우리는 이전 best system 보다 +5.1 F1 향상을 확인했습니다.
4.4 SWAG

Situations With Adversarial Generation(SWAG) dataset은 113,000rodml sentence-pair를 가지고 있습니다. 이 dataset은 grounded common-sense inference를 평가합니다. 주어진 문자으로, 과제는 4개 선택 중 가장 그럴듯한 continuation을 선택합니다. SWAG dataset에서 fine-tuning할 때, 우리는 4개의 input sequences(sentence A)와 가능한 continuation(sentence B)를 구성했습니다. 도입된 유일한 작업별 매개변수는 [CLS] token representation C가 있는 dot product가 softmax layer로 정규화된 각 선택 항목에 대한 점수를 나타내는 벡터입니다.
우리는 3epoch, learning rate 2e-5, batch size 16으로 fine-tune하였스빈다. 결과는 Tabe 4에서 확인할 수 있습니다. BERTLARGE는 ESIM+ELMo 보다 +27.1%, 그리고 OpenAI GPT 보다 +8.3 성능을 보였습니다.
5 Ablation Studies 는 다음 컨텐츠를 이용바랍니다.




댓글 영역