고정 헤더 영역
상세 컨텐츠
본문 제목
[Deep Learning-딥러닝]비용함수 및 유사도-Sum of Squared Error, Cross Entropy, Cosine Similarity
본문
- 비용함수(cost function), 손실함수(loss function) 또는 목적함수(objective function)이라고 부릅니다.
비용함수는 최적화 이론에 기반을 둔 함수이며, 신경망의 지도학습에 사용됩니다. 지도학습은 오차가 최소인 가중치를 구하는 것을 목적으로 하며, 여기서 신경망의 오차를 측정하는 척도가 바로 비용함수입니다. 신경망의 오차가 크면 비용함수의 값도 크고, 신경망의 오차가 작으면 비용함수도 작은 값을 갖습니다. 즉 비용함수는 신경망의 오차에 비례합니다.
신경망 학습에서 비용함수 그래프의 최종 출력은 손실이며, 그 값은 스칼라입니다.
비용함수는 크게 두 가지 형태가 있습니다.
Sum of squared – 제곱합
제곱합은 신경망 연구 초기부터 사용된 비용함수로 델타 규칙을 이용해 오차를 구하고 가중치를 조정합니다. 또한 역전파 알고리즘도 처음에는 제곱으로부터 유도되었습니다.(제곱합 및 델타룰은 “https://ynebula.tistory.com/24” 참고 바랍니다)

신경망 모델의 출력(y)와 정답(d)과 같으면, 오차는0이 됩니다. 반대로 두 값의 차이가 커지면 커질수록 오차의 값도 커집니다. 그래프로 보면 다음과 같습니다.

Cross entropy
교차 엔트로피 오차는 다중 클래스 분류(multi-class classification) 신경망에서 많이 사용합니다.
출력(y)의 범위는 0<y<1 입니다. Cross Entropy 비용함수는 활성함수로 시그모이드 함수나 소프트맥스 함수를 채택한 신경망과 함께 많이 사용됩니다.
수식은 다음과 같습니다.

위 식은 다음 두 개의 수식을 합쳐놓은 거입니다.

- d는 정답 레이블이면 원핫 벡터(one-hot vector)로 표시됨
- yi는 i차원째의 값을 의미함
- N으로 나눠서 평균손실 함수를 구함
미니배치 처리를 고려하면 교차 엔트로피 수식은 다음과 같습니다.

- N개의 데이터
- dji는 j번째 데이터의 i차원째 값을 의미함.
Cross Entropy의 그래프는 다음과 같습니다.
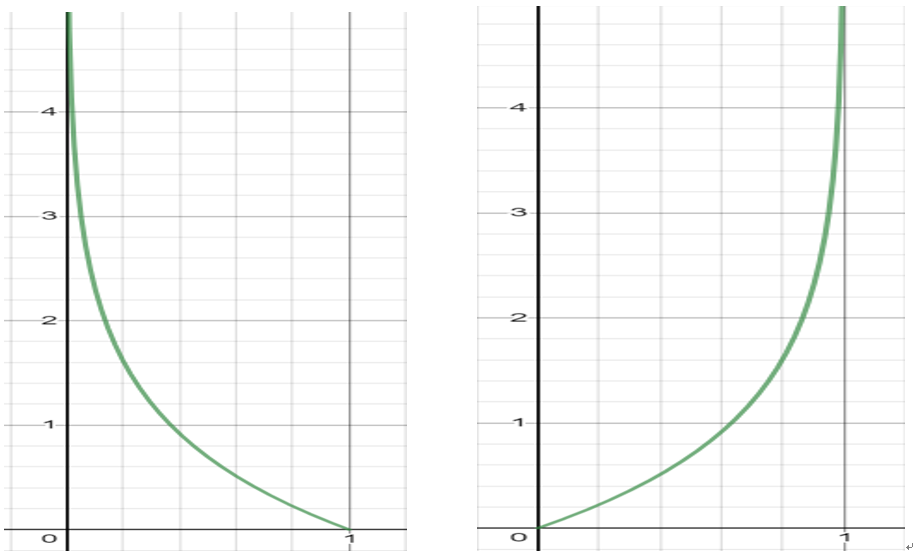
d가 1이고 신경망의 출력 y가 1일 때, 즉 오차(E)가 0일 때는 비용함수의 값도 0입니다. 반면, 신경망의 출력 y가 0에 가까울수록, 즉 오차가 커질수록 비용함수의 값이 급격하게 커집니다.
d가 0이고 신경망의 출력 y가 0일 때, 즉 오차(E)가 0일 때는 비용함수의 값도 0입니다. 반면, 신경망의 출력 y가 1에 가까울수록, 즉 오차가 커질수록 비용함수의 값이 급격하게 커집니다.
Cross Entropy는 오차에 기하급수적으로 비례하는 함수라는 사실입니다. 즉 같은 오차라도 Cross Entropy 함수가 훨씬 더 민감하게 반응합니다. 이런 이유로 대개의 경우에는 Cross Entropy 함수로부터 유도된 학습 규칙의 성능이 더 좋다고 합니다. 회귀 문제와 같이 불가피한 경우가 아니면 Cross Entropy 함수로부터 유도된 학습 규칙을 사용하기를 권장합니다.
Cross Entropy 역전파 알고리즘
다음은 출력 노드의 활성함수가 시그모이드 함수일 경우에 Cross entropy 함수로부터 유도된 역전파 알고리즘으로 다층 신경망을 학습시키는 과정입니다.
1. 신경망의 가중치를 적당한 값으로 초기화합니다.
2. 학습 데이터 {입력, 정답}에서 ‘입력’을 신경망에 입력해 출력값을 얻습니다. 이 출력값과 해당 입력의 ‘정답’을 비교해 오차를 구하고, 출력 노드들의 델타를 계산합니다.

3. 출력 노드의 델타를 역전파 시켜 바로 앞 은닉 노드들의 델타를 계산합니다.

4. 단계3을 입력층 바로 앞 은닉층까지 차례로 반복합니다.
5. 신경망의 가중치를 다음의 학습 규칙으로 변경합니다.
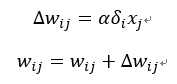
6. 모든 학습 데이터에 관해 2~5를 반복합니다.
7. 신경망이 충분히 학습될 때까지 단계 2~6을 반복합니다.
Regularization – 정칙화
Regularization은 과적합을 예방하려는 방법입니다. 이는 모델을 최대한 단순하게 만드는 것입니다. Regularization은 비용함수에 가중치의 크기를 모두 더한 것으로 수식은 다음과 같습니다.

λ 은 비용함수에 연결 가중치의 크기를 얼마나 반영할지를 결정하는 값입니다. 오차가 0이라도 가중치의 값이 크면 비용함수는 큰 값을 갖게 됩니다. 따라서 가중치의 크기도 되도록 작아야 합니다. 그런데 어떤 가중치의 값이 충분히 작으면 해당 노드 사이의 연결은 끊긴 것과 마찬가지가 됩니다. 결국 불필요한 노드 사이의 연결이 없어져 신경망은 더 간단한 형태가 됩니다. 또한 가중치의 크기를 작게 하면 신경망의 과적합 문제를 개선하는데 도움이 됩니다.
Cosine Similarity – 코사인 유사도
코사인 유사도는 “두 벡터가 가리키는 방향이 얼마나 비슷한가”를 나타냅니다. 두 벡터의 방향이 완전히 같다면 유사도는 1이되고, 완번히 반대면 -1이 됩니다.
두 벡터 x, y가 다은과 같다면 코사인 유사도는 다음 식으로 정의됩니다.
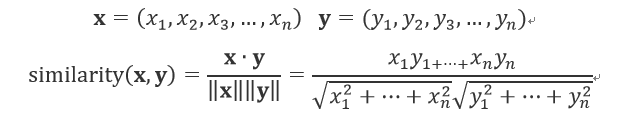
분자에는 벡터의 내적이, 분모에는 각 벡터의 노름(norm)으로 정의됩니다. 위 식의 핵심은 벡터를 정규화하고 내적을 구하는 것입니다(노름은 벡터의 크기를 나타낸 것으로 여기에서는 L2노름을 계산합니다. L2노름은 벡터의 각 원소를 제곱해 더한 후 다시 제곱근을 구해 계산합니다).
Source
위 이론에 대한 소스구현 내용은 아래 포스팅에서 확인가능합니다. git 소스도 아래 포스트에서 확인할 수 있습니다.
[Sum of squared]
https://ynebula.tistory.com/25
[Deep Learning]Backpropagation - 역전파 구현
이번 포스팅은 MLP 구조를 이용하여 XOR 연산법을 구현하는 방법에 대해서 알아보겠습니다. 선행 학습으로 “경사하강법”, “Solving XOR Problem with MLP”과 “Back propagation&rdq..
ynebula.tistory.com
[Cross entropy]
https://ynebula.tistory.com/33
[Deep Learning]Cross Entropy 알고리즘 소스 구현 및 Tensoflow 구현
소스 구성은 Python을 이용한 학습 알고리즘 구현과 Tensorflow를 이용한 구현 두 가지입니다. Cross Entropy에 대한 이론은 “https://ynebula.tistory.com/28” 포스팅을 참고 바랍니다. 학습 내용 및..
ynebula.tistory.com
감사합니다.
[참고자료]
딥러닝 첫걸음
haykin.neural-networks.3ed.2009
'Artificial Intelligence' 카테고리의 다른 글
| [Deep Learning-딥러닝]Multi Classification - 다범주분류 및 소스프맥스 소스 구현 (0) | 2019.08.19 |
|---|---|
| [Deep Learning-딥러닝]Cross Entropy 알고리즘 소스 구현 및 Tensoflow 구현 (0) | 2019.08.15 |
| [Reinforce Learning]강화학습 정의 (0) | 2019.08.09 |
| [Deep Learning-딥러닝]가중치 조정 - Momentum (0) | 2019.08.08 |
| [Deep Learning-딥러닝]Backpropagation (역전파) 및 Delta Rule을 이용한 가중치 조정 방법 소스 구현 - XOR 연산 (0) | 2019.08.07 |




댓글 영역